

Увод у дата мининг
Ово је метода вађења података која се користи за постављање елемената података у њихове сличне групе. Кластер је поступак поделе објеката података на подкласе. Квалитет кластера зависи од методе коју смо користили. Кластерирање се назива и сегментација података јер су велике групе података подељене по сличности.
Шта је груписање у копању података?
Кластерирање је групирање одређених објеката на основу њихових карактеристика и сличности. Што се тиче копања података, ова методологија дели посебне податке који су најприкладнији за жељену анализу помоћу посебног алгоритма придруживања. Ова анализа омогућава да предмет не буде део или строго део кластера, што се назива тврдом партицијом овог типа. Међутим, глатке партиције сугеришу да сваки објект у истом степену припада групи. Могу се створити одређеније поделе попут објеката из више кластера, један кластер може бити приморан да учествује или се у групним односима могу конструисати чак и хијерархијска стабла. Овај датотечни систем се може поставити на различите начине на основу различитих модела. Ови различити алгоритми односе се на сваки модел, разликујући њихова својства као и њихове резултате. Добар алгоритам кластера је у стању да идентификује кластер независно од облика кластера. Постоје 3 основне фазе алгоритма групирања које су приказане као доле
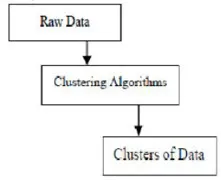
Кластерирање алгоритама у Рударству података
Зависно од недавно описаних модела кластера, многи кластери могу се користити за дијељење информација у скуп података. Треба рећи да свака метода има своје предности и мане. Избор алгоритма зависи од својстава и природе скупа података.
Методе кластерирања за вађење података могу се приказати у наставку
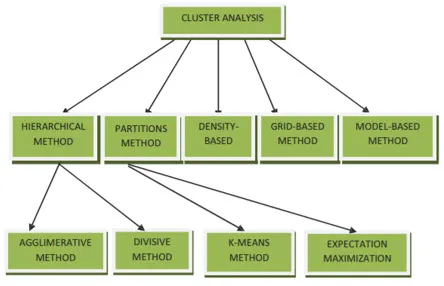
- Метода заснована на партиционирању
- Метода заснована на густоћи
- Метода заснована на стероидима
- Хијерархијски метод
- Метода заснована на мрежи
- Метода заснована на моделу
1. Метода заснована на партиционирању
Алгоритам партиције дијели податке на више подскупова.
Претпоставимо да алгоритам за партиционирање гради партицију података јер су к и н предмети присутни у бази података. Стога ће свака партиција бити представљена као к ≤ н.
Ово даје идеју да је класификација података у к групама, што може бити приказано у наставку
На слици 1 приказане су оригиналне тачке у групирању

На слици 2 приказано је групирање партиција након примјене алгоритма
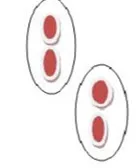
Ово указује да свака група има најмање један објект, као и сваки објект, мора припадати тачно једној групи.
2. Метода заснована на густоћи
Ови алгоритми производе кластере на одређеној локацији засновани на високој густини учесника скупа података. Он агрегира неки појам распона за чланове групе у кластерима до нивоа стандардне густине. Такви процеси могу бити слабији у детекцији површина у групи.
3. Метода заснована на центру
Готово на сваки кластер упућује вектор вредности у овој врсти ос групирања. У поређењу са другим кластерима, сваки је објект дио кластера са минималном разликом вриједности. Број кластера би требало да буде унапред дефинисан, и то је највећи проблем алгоритма овог типа. Ова методологија је најближа предмету идентификације и широко се користи за проблеме оптимизације.
4. Хијерархијски метод
Метода ће створити хијерархијску декомпозицију датог скупа података. На основу како се формира хијерархијска декомпозиција, можемо класификовати хијерархијске методе. Ова метода је дата на следећи начин
- Агломеративни приступ
- Дивизијски приступ
Агломеративни приступ је такође познат и као присутан приступ. Овдје почињемо са сваким објектом који чини засебну групу. Наставља са спајањем објеката или група блиских заједно
Дивизијски приступ је такође познат и као приступ одоздо нагоре. Почињемо са свим објектима у истом кластеру. Ова метода је крута, тј. Никада је не може поништити након фузије или поделе
5. Метода заснована на мрежи
Методе засноване на мрежи раде у простору објекта уместо дељења података у мрежу. Мрежа је подељена на основу карактеристика података. Овом методом лако је управљати не нумеричким подацима. Редослијед података не утјече на подјелу мреже. Важна предност мрежног модела је што омогућава већу брзину извршења.
Предности хијерархијског кластерирања су следеће
- Применљиво је на било који тип атрибута.
- Омогућава флексибилност која је повезана са нивоом зрнатости.
6. Метода заснована на моделу
Ова метода користи хипотезирани модел заснован на дистрибуцији вероватноће. Кластерирањем функције густине, ова метода лоцира кластере. Одраз је просторне расподјеле података.
Примена кластерирања у Рударству података
Кластерирање може помоћи у многим областима као што су биологија, биљке и животиње класификоване према њиховим својствима као и у маркетингу. Кластерирање ће помоћи идентификацији купаца одређеног клијента са сличним понашањем. У многим апликацијама, као што су истраживање тржишта, препознавање образаца, обрада података и слика, анализа кластера користи се у великом броју. Кластерирање такође може помоћи оглашивачима у њиховој корисничкој бази да пронађу различите групе. Њихове групе купаца могу се дефинисати обрасцима куповине. У биологији се користи за одређивање биљних и животињских таксономија, за категоризацију гена сличне функционалности и за увид у структуре својствене популацији. У земаљској бази за посматрање, кластерирање такође олакшава проналажење подручја сличне употребе у земљи. Помаже у идентифицирању групација кућа и станова према врсти, вриједности и одредишту кућа. Групирање докумената на вебу је такође корисно за откривање информација. Анализа кластера је алат за стицање увида у дистрибуцију података ради посматрања карактеристика сваког кластера као функције вађења података.
Закључак
Кластерирање је важно код ископавања података и његове анализе. У овом чланку смо видели како се кластерирање може обавити применом различитих алгоритама кластера, као и његовом применом у стварном животу.
Препоручени чланак
Ово је водич за шта је кластерирање у Рударству података. Овде смо разговарали о концептима, дефиницији, карактеристикама, примени кластерирања у Рударству података. Можете и да прођете кроз друге наше предложене чланке да бисте сазнали више -
- Шта је обрада података?
- Како постати аналитичар података?
- Шта је СКЛ убризгавање?
- Дефиниција шта је СКЛ Сервер?
- Преглед архитектуре рударјења података
- Кластерирање у машинском учењу
- Хијерархијски алгоритам кластерирања
- Хијерархијско кластерирање | Агломеративно и подељено кластерирање