
 Разлике између надзираног учења и дубоког учења
Разлике између надзираног учења и дубоког учења
У супервизираном учењу, подаци о обуци које храните алгоритмом укључују жељена решења, која се називају ознаке. Типичан надзирани задатак учења је класификација. Филтар нежељене поште је добар пример тога: обучен је са многим примерима е-поште заједно са њиховом класом (нежељеном снагом или пршутом) и мора научити како да класификује нове поруке е-поште.
Дубоко учење је покушај опонашања активности у слојевима неурона у неокортексу, што је око 80% мозга где се размишљање догађа (У људском мозгу постоји око 100 милијарди неурона и 100 ~ 1000 билиона синапси). Назван је дубоким јер има више од једног скривеног слоја неурона који помажу у вишеструком стању нелинеарне трансформације карактеристика
Упоређивање супервизираног учења са дубоким учењем (Инфограпхицс)
Испод је топ 5 поређења између супервизираног учења и дубоког учења 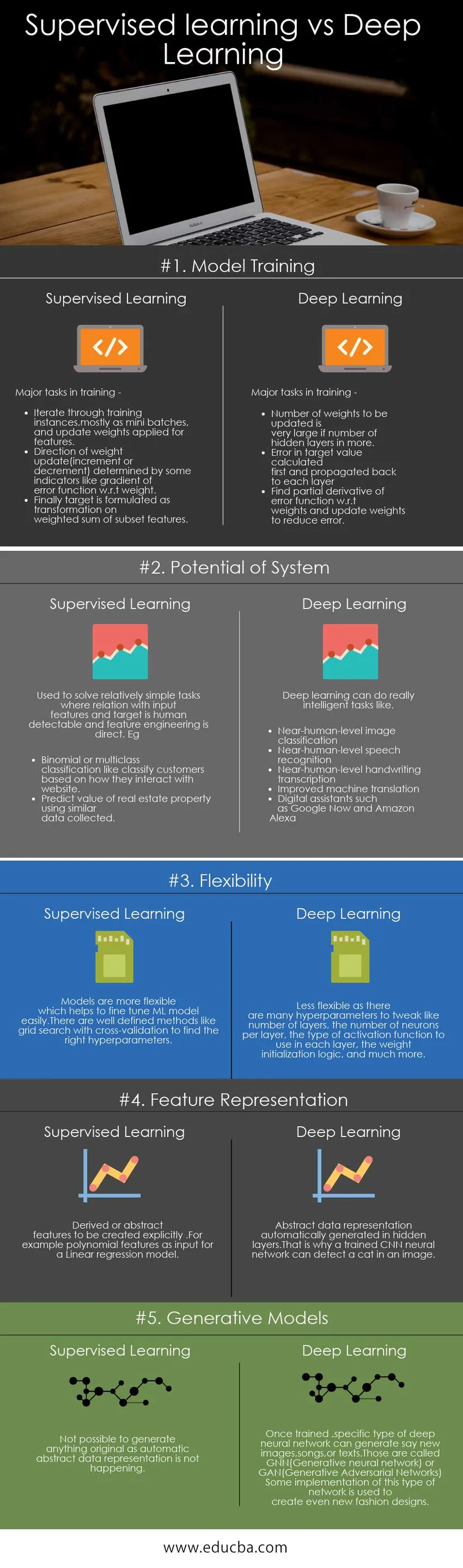
Кључне разлике између надзираног учења и дубоког учења
Оба супервизираног учења вс дубинског учења популарни су избор на тржишту; Хајде да разговарамо о неким главним разликама између надзираног учења и дубоког учења:
● главни модели -
Важни надгледани модели су -
○ к-Најближи суседи - користе се за класификацију и регресију
○ Линеарна регресија - за предвиђање / регресију
○ Логистичка регресија - за класификацију
Вецтор Подршка векторских машина (СВМ) - Користи се за класификацију и регресију
Ес Дрвеће одлучивања и случајне шуме - задаци класификације и регресије
Најпопуларније дубоке неуронске мреже:
● Вишеслојни перцептрони (МЛП) - најосновнији тип. Ова мрежа је генерално почетна фаза изградње друге софистицираније дубоке мреже и може се користити за било који надгледани регресијски или класификациони проблем
● Аутоенцодери (АЕ) - Мрежа има алгоритме учења који нису надгледани за учење функција, смањење димензија и откривање вањских димензија
● Конволуциона неуронска мрежа (ЦНН) - посебно погодна за просторне податке, препознавање објеката и анализу слике користећи вишедимензионалне неуронске структуре. Један од главних разлога популарности дубоког учења у последње време је захваљујући ЦНН-у.
● Понављајућа неуронска мрежа (РНН) - РНН -ови се користе за секвенцијалну анализу података као што су временска серија, анализа осећања, НЛП, превођење језика, препознавање говора, наслов текста. Једна од најчешћих врста РНН модела је мрежа краткорочне меморије (ЛСТМ).
● Подаци о обуци - Као што је раније споменуто, надгледани модели требају податке о обуци са налепницама. Али дубинско учење може да обрађује податке са или без налепница. Неке неуронске мрежне архитектуре могу бити без надзора, као што су аутоенкодери и ограничене Болтзманнове машине
● Избор могућности - Неки надгледани модели могу да анализирају функције и изабрани подскуп функција да одреде циљ. Али већину времена ово треба решити у фази припреме података. Али у Дееп Неурал Нетворкс појављују се нове функције, а нежељене функције се одбацују као напредак учења.
● Приказивање података - У класичним надзираним моделима апстрахирање улазних функција на високом нивоу се не ствара. Коначни модел који покушава предвидјети излаз примјеном математичких трансформација на подскуп улазних значајки.
Али у дубоким неуронским мрежама, апстракције улазних карактеристика се формирају интерно. На пример, док преводи текст, неуронска мрежа прво претвара улазни текст у интерно кодирање, а затим апстрактно представља трансформише у циљни језик.
● Оквирни - Надгледани МЛ модели подржани су од много опћих МЛ оквира на различитим језицима - Апацхе Махоут, Сцикит Леарн, Спарк МЛ су неки од ових.
Већински оквири дубоког учења пружају апстракцији прилагођену програмерима да лако креира мрежу, брине о дистрибуцији рачунања и има подршку за ГПУс.Цаффе, Цаффе2, Тхеано, Торцх, Керас, ЦНТК, ТенсорФлов су популарни оквири.Тенсорфлов од Гооглеа се широко користи сада уз активну подршку заједнице.
Табела упоређеног учења против дубинског учења
Испод је неколико кључних поређења између супервизираног учења и дубоког учења
| Основе поређења између надзираног учења и дубоког учења | Надзирано учење | Дубоко учење |
| Тренинг модела | Главни задаци у обуци -
| Главни задаци у обуци -
|
| Потенцијал система | Користи се за решавање релативно једноставних задатака где је однос са улазним особинама и метом могуће открити људима, а инжењеринг значајки је директан. На пример :
| Дубоко учење може обавити заиста интелигентне задатке попут
|
| Флексибилност | Модели су флексибилнији што омогућава лако подешавање МЛ модела. Постоје добро дефинисане методе попут претраживања мреже са унакрсном валидацијом како би се пронашли прави хиперпараметри | Мање флексибилно јер постоји много хиперпараметара за подешавање попут броја слојева, броја неурона по слоју, врсте функције активације коју треба користити у сваком слоју, логике иницијализације тежине и још много тога. |
| Заступање значајки | Изведене или апстрактне карактеристике креирају експлицитно. На пример функције полинома као улаз за модел линеарне регресије | Апстрактни приказ података аутоматски се генерише у скривеним слојевима. Зато обучена ЦНН неуронска мрежа може открити мачку на слици. |
| Генеративни модели | Није могуће генерирати ништа оригинално јер се аутоматски не приказује апстрактно представљање података | Једном обучени, одређена врста дубоке неуронске мреже може створити нове слике, песме или текстове. Они се називају ГНН (Генеративе неуронска мрежа) или ГАН (Генеративе Адверсариал Нетворкс)
Неке примене ове врсте мреже користе се за стварање нових модних дизајна |
Закључак - Надзирано учење вс Дубоко учење
Прецизност и способност ДНН (Дееп Неурал Нетворк) мрежа се знатно повећала у последњих неколико година. Зато су сада ДНН-ови подручје активног истраживања и, вјерујемо, има потенцијал за развој Општег интелигентног система. У исто време, тешко је објаснити зашто ДНН даје одређени излаз што отежава фино подешавање мреже. Дакле, ако се проблем може решити помоћу једноставних МЛ модела, топло се препоручује да га користите. Због ове чињенице, једноставна линеарна регресија ће бити релевантна чак и ако је развијен општи интелигентни систем који користи ДНН.
Препоручени чланак
Ово је био водич за разлике између супервизираног учења и дубоког учења. Овде такође расправљамо о кључним разликама супервизираног учења против дубоког учења са инфографиком и табелом упоређивања. Можда ћете такође погледати следеће чланке -
- Надзирано учење вс ојачавање учења
- Надзирано учење вс Ненадзирано учење
- Неуронске мреже вс дубоко учење
- Машинско учење и предвиђање аналитике
- ТенсорФлов вс Цаффе: Које су разлике
- Шта је надзирано учење?
- Шта је појачано учење?
- Топ 6 поређења између ЦНН и РНН