
Разлика између машинског учења и предиктивне аналитике
Машинско учење је област у рачунарској науци која ових дана све више скаче и веже се. Недавни напредак у хардверским технологијама који је резултирао масовним порастом рачунарске снаге као што су ГПУ (графичке процесорске јединице) и напредовање у неуронским мрежама, машинско учење је постало језива реч. У основи, користећи технике машинског учења, можемо изградити алгоритме за вађење података и видети важне скривене информације из њих. Предиктивна аналитика такође је део домена машинског учења који је ограничен да предвиђа будући резултат на основу података на основу претходних образаца. Иако се предиктивна аналитика користи већ више од две деценије углавном у банкарском и финансијском сектору, примена машинског учења у последње време добија значајну улогу у алгоритмима попут детекције предмета из слика, текстуалне класификације и система препорука.
Машинско учење
Машинско учење интерно користи статистике, математику и основе рачунарске науке за изградњу логике за алгоритме који могу вршити класификацију, предвиђање и оптимизацију у реалном времену, као и у групном режиму. Класификација и регресија су две главне класе проблема у оквиру машинског учења. Да разумемо детаљно и машинско учење и предиктивну аналитику.
Класификација
Под тим групама проблема, склони смо да класификујемо објекат на основу његових различитих својстава у једну или више класа. На пример, класификовање клијента банке да испуњава услове за кредит од куће или не на основу његове / њене кредитне историје. Обично бисмо за купца имали доступне податке о трансакцијама као што су његова старост, приход, образовање, радно искуство, индустрија у којој ради, број издржаваних чланова, месечни трошкови, претходни кредити ако постоје, његов образац потрошње, кредитна историја итд. … и на основу ових информација склони бисмо израчунати да ли му треба дати зајам или не.
Постоји много стандардних алгоритама машинског учења који се користе за решавање проблема класификације. Логистичка регресија је једна таква метода, вероватно најчешће коришћена и најпознатија, такође и најстарија. Поред тога, имамо и неке од најнапреднијих и најкомпликованијих модела, од стабла одлучивања до случајне шуме, АдаБоост, КСП појачање, векторске машине за подршку, наивну кожу и неуралну мрежу. Од последњих неколико година, дубоко учење иде у први план. За класификацију слика се обично користи неуронска мрежа и дубоко учење. Ако постоји стотина хиљада слика мачака и паса и желите да напишете код који аутоматски може раздвојити слике мачака и паса, можда бисте желели да потражите методе дубоког учења попут конволуционе неуронске мреже. Торцх, кафе, проток сензора итд. Су неке од популарних библиотека у питхон-у за дубинско учење.
За мерење тачности регресијских модела користе се метрике попут лажне позитивне стопе, лажно негативне стопе, осетљивости итд.
Регресија
Регресија је друга класа проблема у машинском учењу где покушавамо да предвидимо непрекидну вредност променљиве уместо класе за разлику од класичних проблема. Регресијске технике се обично користе за предвиђање цене деоница акција, продајне цене куће или аутомобила, потражње за одређеним предметом, итд. Када играчке временске серије такође уђу у игру, проблеми регресије постају врло занимљиви за решавање. Линеарна регресија са обичним најмање квадратом један је од класичних алгоритама машинског учења у овој домени. За образац заснован на временским серијама користе се АРИМА, експоненцијални помични просјек, пондерирани покретни просјек и једноставан помични просјек.
За мерење тачности регресијских модела користе се метрике попут средње грешке квадрата, апсолутне средње квадратне грешке, квадратне грешке мере и сл.
Предиктивна аналитика
Постоје неке области преклапања између машинског учења и предиктивне аналитике. Док уобичајене технике попут логистичке и линеарне регресије спадају и у машинско учење и у предиктивну аналитику, напредни алгоритми попут стабла одлука, случајних шума итд. Су у основи машинско учење. Под предиктивном аналитиком, циљ проблема остаје врло узак тамо гдје је намјера израчунати вриједност одређене варијабле у будућем тренутку. Предиктивна аналитика је веома оптерећена статистиком, док је машинско учење више спој статистике, програмирања и математике. Типични аналитичар предвиђања троши своје време рачунајући т квадрат, ф статистику, Иннова, цхи-квадрат или обични најмање квадрат. Питања попут тога да ли су подаци нормално дистрибуирани или искривљени, треба ли употребљавати дистрибуцију ученика или користити кривуљу звона, ако их алфа узима на 5% или 10% грешке све време. Они у детаље траже ђавола. Инжењер машинског учења не мучи многе од ових проблема. Њихова главобоља је потпуно другачија, они се налазе заглављени у побољшању тачности, смањењу лажно позитивних стопа, руковању вањима, нормализацији опсега или к олацији валидације.
Предвиђачки аналитичар углавном користи алате попут екцел. Сценарио или тражење циља су им омиљени. Повремено користе ВБА или мицрос и тешко пишу дуготрајни код. Инжењер машинског учења све своје вријеме проводи пишући компликоване кодове изван уобичајеног разумијевања, користи алате попут Р, Питхон, Саас. Програмирање је њихов главни посао, поправљање грешака и тестирање различитих пејзажа свакодневном рутином.
Те разлике такође доносе велику разлику у њиховој потражњи и платама. Док су јучерашњи аналитичари предиктивни, машинско учење је будућност. Типичном инжењеру машинског учења или знанственицима података (како се данас углавном називају) плаћају се 60-80% више од типичног софтверског инжењера или предиктивног аналитичара по том питању и они су кључни покретач у данашњем свету омогућеном технологијом. Убер, Амазон и сада самовозећи аутомобили могући су и само због њих.
Упоређивање између машинског учења и предиктивне аналитике (инфограпхицс)
Испод је топ 7 поређења између машинског учења и предиктивне аналитике
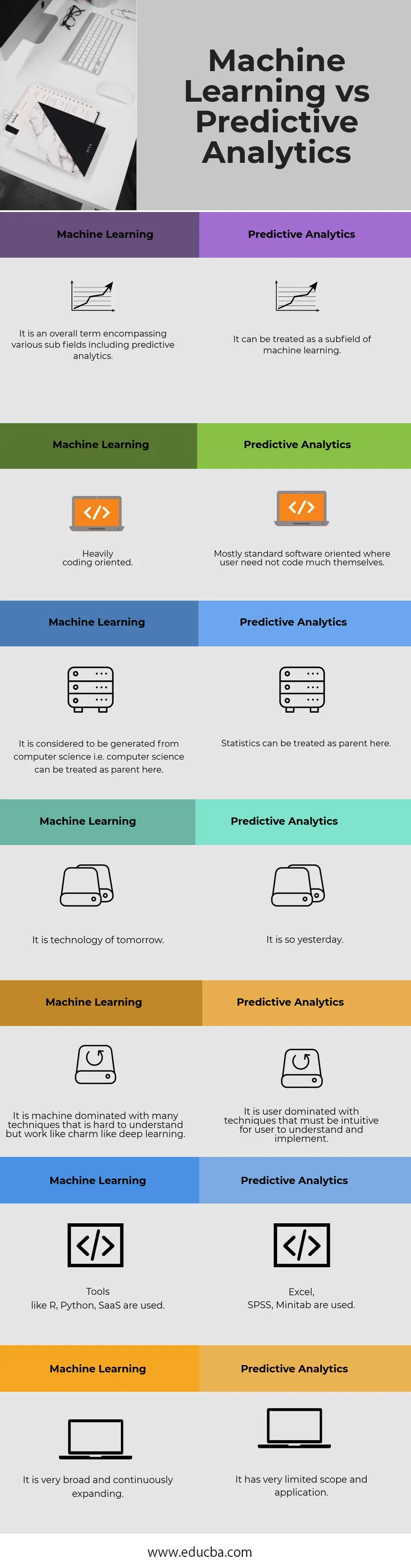
Таблица машинског учења и предвиђања аналитичке предиктивне анализе
Испод је детаљно објашњење Машинског учења вс Предицтиве Аналитицс
| Машинско учење | Предиктивна аналитика |
| То је свеобухватни појам који обухвата различита потпоља укључујући предиктивну аналитику. | Може се третирати као потпоље машинског учења. |
| Јако оријентисано на кодирање. | Углавном стандардно софтверски оријентисани када корисници не морају много да сами кодирају |
| Сматра се да настаје из рачунарске науке, тј. Рачунарска наука овде се може третирати као родитељ. | Овде се статистика може третирати као родитељ. |
| То је технологија сутра. | Тако је јуче. |
| То је машина којом доминирају многе технике које је тешко разумети, али делују попут шарма као што је дубоко учење. | Корисник доминира техникама које морају бити интуитивне да би их корисник могао разумети и применити. |
| Користе се алати попут Р, Питхон, СааС. | Користе се Екцел, СПСС, Минитаб. |
| Веома је широк и непрекидно се шири. | Има веома ограничен опсег и примену. |
Закључак - Машинско учење вс предвиђање аналитике
Из горње дискусије и о „Машинском учењу“ и „Предицтиве Аналитицс“ јасно је да је предиктивна аналитика у основи потпоље машинског учења. Машинско учење је свестраније и способно је да реши широк спектар проблема.
Препоручени чланак
Ово је водич за Машинско учење против предиктивне аналитике, њихово значење, упоређивање главе до главе, кључне разлике, табела упоређивања и закључак. Такође можете погледати следеће чланке да бисте сазнали више -
- Научите велике податке против машинског учења
- Разлика између науке о подацима и машинског учења
- Поређење између Предицтиве Аналитицс-а и Дата Сциенце-а
- Анализа података против предиктивне аналитике - која је корисна