
Увод у ојачавање учења
Учење ојачавања је врста машинског учења, па је такође део вештачке интелигенције, када се примењују на системе, системи изводе кораке и уче на основу резултата корака како би постигли сложени циљ који је систем постављен да постигне.
Схватите ојачавање учења
Покушајмо да учимо појачање уз помоћ два једноставна случаја употребе:
Случај бр. 1
У породици је беба и она је тек почела ходати и сви су пресрећни због тога. Једног дана, родитељи покушавају да поставе циљ, пусти нас да дођемо до кауча и видимо да ли је беба у стању да то уради.
Резултат случаја 1: Беба успешно стиже до сета и тако су сви у породици врло срећни што ово виде. Одабрани пут сада доноси позитивну награду.
Бодови: Награда + (+ н) → Позитивна награда.
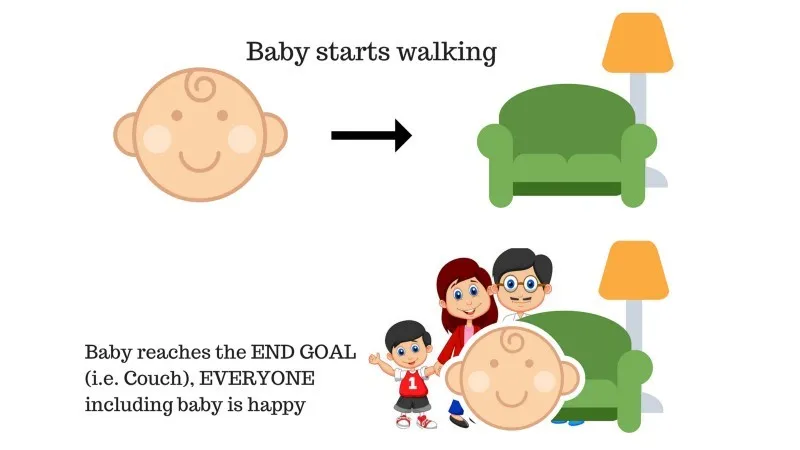
Извор: хттпс : //имагес.апп.гоо.гл/пГЦКСЈ1Н1бзЛАер126
Случај бр. 2
Беба није успела да се попне на кауч и беба је пала. То боли! Шта би вероватно могао бити разлог? На путу до кауча могу постојати неке препреке и беба је пала на препреке.
Резултат случаја 2: Беба пада на неке препреке и плаче! Ох, то је било лоше, научила је, да следећи пут не упаднем у замку препрека. Одабрани пут сада долази са негативном наградом.
Бодови: Награде + (-н) → Негативна награда.
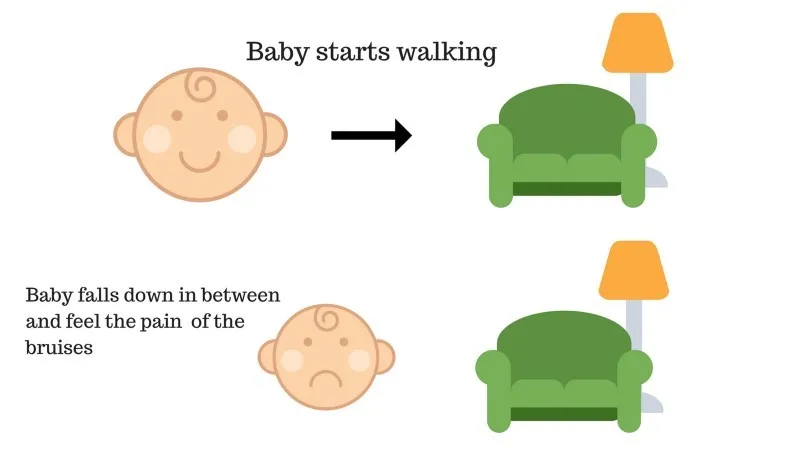
Извор: хттпс : //имагес.апп.гоо.гл/ФРфд8цУкрКРЛе6сЗ7
Ово сада смо видели случајеве 1 и 2, учење појачања у концепту чини исто, осим што није људско, већ се обавља рачунски.
Коришћење корака за појачање
Да разумемо учење ојачања тако да поступно уведемо средство за појачање. У овом примеру, наш агент за учење ојачања је Марио, који ће самостално научити да игра:
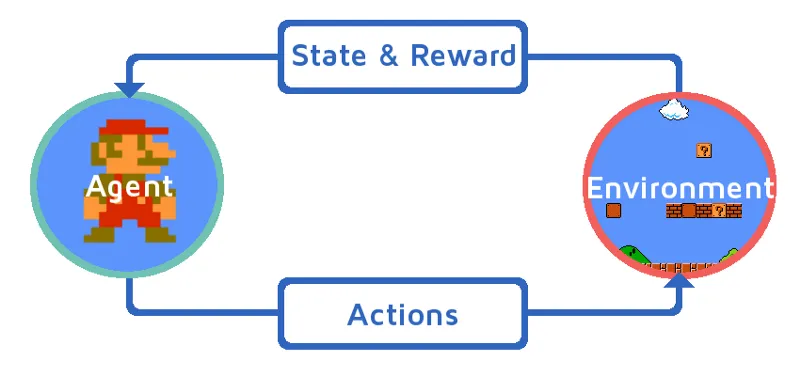
Извор: хттпс://имагес.апп.гоо.гл/Кј44увБзВзМв1КзЕ9
- Тренутно стање Марио игре окружења је С_0. Јер игра још није почела и Марио је на свом месту.
- Затим се игра покреће и Марио креће, Марио тј. РЛ агент предузима и делује, рецимо А_0.
- Сада је стање окружења за игру постало С_1.
- Такође, агенту РЛ-а, тј. Марио-у је сада додељено неко позитивно наградно место, Р_1, вероватно зато што је Марио још увек жив и није било никакве опасности.
Сада ће се горња петља наставити све док Марио коначно не умре или Марио не стигне на своје одредиште. Овај модел ће континуирано излазити акције, награде и стања.
Награде за максимизацију
Циљ учења ојачања је максимизирати награде узимајући у обзир и неке друге факторе попут попуста на награде; убрзо ћемо објаснити шта се подразумева под попустом уз помоћ илустрације.
Кумулативна формула за снижене награде је:
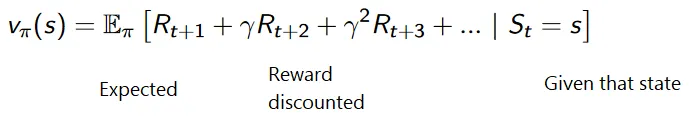
Награде са попустом
Разумејмо то на примеру:
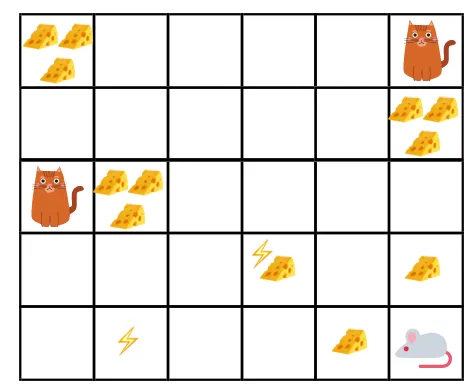
- На датој слици, циљ је да миш у игри мора појести што више сира прије него што га мачка поједе или без електрошокирања.
- Сада можемо претпоставити да што смо ближи мачки или електричном замку, то је већа вероватноћа да ће миш појести или шокирати.
- То подразумева, чак и ако имамо пун сир у близини струјног удара или у близини мачке, што је ризичније да идемо тамо, боље је јести сир који се налази у близини како не би било ризика.
- Дакле, иако имамо један „блок1“ сира који је пун и удаљен је од мачке и електричног удара и други „блок2“, који је такође пун, али је близу мачке или блока струјног удара, каснији блок сира, тј. „блоцк2“, биће снижен у наградама у односу на претходни.
Извор: хттпс : //имагес.апп.гоо.гл/8КрХ78ФјмРВс5Вкк8
Извор: хттпс : //цдн-имагес-1.медиум.цом/мак/800/1*л8вл4хЗвЗАиЛУ56хТ9вЛлг.пнг
Врсте усавршавања учења
Испод су две врсте учења ојачања са њиховим предностима и недостацима:
1. Позитивно
Када се снага и учесталост понашања повећају због појаве неког одређеног понашања, то је познато као позитивно учвршћивање учења.
Предности: Перформансе су максималне, а промена остаје дуже време.
Недостаци: Резултати се могу умањити ако имамо превише појачања.
2. Негативно
То је јачање понашања, највише због тога што негативни термин нестаје.
Предности: Понашање се повећава.
Недостаци: Само минимално понашање модела може се достићи уз помоћ негативног учења ојачања.
Где треба да користи учење ојачања?
Ствари које се могу урадити помоћу појачаног учења / примјера. Следе области у којима се ових дана користи учење појачања:
- Здравствена заштита
- образовање
- Игре
- Компјутерски вид
- Пословни менаџмент
- Роботика
- Финансије
- НЛП (Обрада природног језика)
- Превоз
- Енергија
Каријере у јачању учења
Заиста постоји извештај са места посла, пошто је РЛ грана машинског учења, а према извештају, Машинско учење је најбољи посао 2019. Испод је кратки снимак извештаја. Према тренутним трендовима, инжењери машинског учења долазе са огромном просечном платом од 146, 085 долара и са стопом раста од 344 процента.
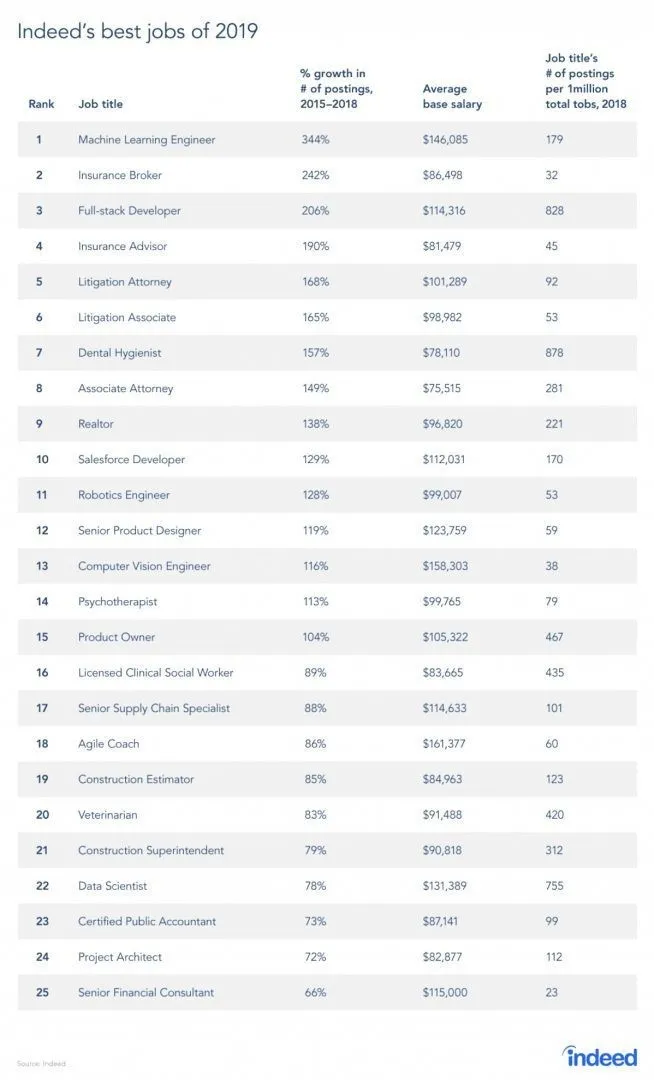
Извор: хттпс : //и0.вп.цом/ввв.артифициалинтеллигенце-невс.цом/вп-цонтент/уплоадс/2019/03/индеед-топ-јобс-2019-бест.јпг?в=654&ссл=1
Вештине за ојачавање учења
Испод су вештине потребне за учење ојачања:
1. Основне вештине
- Вероватноћа
- Статистика
- Дата Моделинг
2. Вештине програмирања
- Основе програмирања и рачунарске науке
- Дизајн софтвера
- Способна је применити библиотеке и алгоритме машинског учења
3. Машинско учење програмских језика
- Питхон
- Р
- Иако постоје и други језици на којима се могу обликовати модели машинског учења, као што су Јава, Ц / Ц ++, али су Питхон и Р језици који се највише користе.
Закључак
У овом смо чланку започели с кратким уводом о учењу појачања, а затим смо дубоко заронили у раду на РЛ-у и различитим факторима који су укључени у рад на РЛ моделима. Тада смо дали неколико примера из стварног света да бисмо још боље разумели ту тему. На крају овог чланка требало би добро разумети рад учења ојачања.
Препоручени чланци
Ово је водич за Шта је појачано учење ?. Овде смо расправљали о функцији и разним факторима који су укључени у развој модела ојачања за учење, са примерима. Можете и да прођете кроз остале сродне чланке да бисте сазнали више -
- Врсте алгоритама машинског учења
- Увод у вештачку интелигенцију
- Алати за вештачку интелигенцију
- ИоТ платформа
- Топ 6 језика за програмирање машинског учења